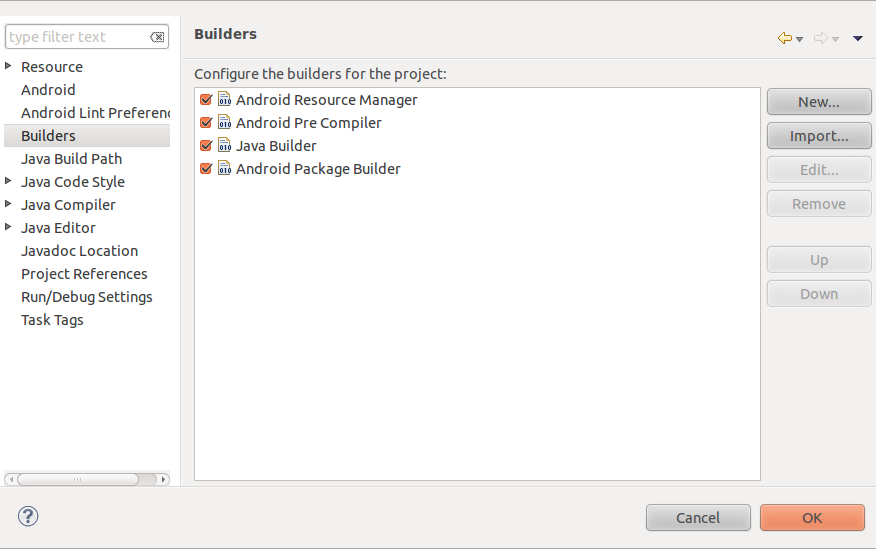
It’s been a long time since my last post in my blog because insert-apology-never-used-here, but I would like to share results of spending many evenings looking for an alternative to use NFC on Raspberry Pi.
First weeks, I was focusing on running the ACS NFC ACR122u reader, previously used for me in the company I’m currently working in order to investigate Linux interaction of this reader. Bad luck, I though using Raspberry Pi and well known automagic library nfcpy find out a NFC stable alternative will be easiest. Not this way. Rasperry Pi installs a Linux system, right, certainly a Debian. But arch isn’t i386, is ARM (properly for small devices as smartphones and tablets). Despite this works regularly, ACR122u reader fails randomly and with no explanation. As told me an expert in this game as Stephen Tiedemann (nfcpy creator) in this thread, also reader is the worst choice to do this, Raspberry USB subsystem seems to be very unstable for these peripherals (mouse, keyboards and basic material works like a charm).

El lector NFC ACR122U
With the first knock-out, I decide don’t follow recommendations from Stephen to check a PN532 board, connectable via serie like Arduino using a bit more electronics, boards and other. Instead of this, I made a small investment for the EXPLORE-NFC NXP PN512 board, which have not support from nfcpy but have code examples written in pure C. This board will connect to the GPIO expansion port like an USB connector.

La placa explore-nfc
There are programs ready for three NFC operation modes: tag, card emulation and P2P. Handicap is P2P mode only have PUT operation coded (receive from Raspberry) but not GET operation (raspberry receive from smartphone). I wrote a Python/GTK program as graphical interface towards this P2P program, in order to check PUT operation. You can see the result in the attached video, where I check too Card Emulation mode.
* EXPLORE-NFC sample code:
http://www.element14.com/community/docs/DOC-65447/l/explore-nfc-software-and-project?ICID=knode-devkitnfc-quick
* Buy EXPLORE-NFC (check Business in the dialog window, although you are a particular):
http://es.farnell.com/jsp/displayProduct.jsp?sku=2366201&CMP=KNC-GES-FES-GEN-SKU-MDC
* Python/GTK personal graphical demo code:
https://bitbucket.org/jialvarez/raspberry-mpos
 Be the first to like.
Be the first to like.