OCS Inventory es una fantástica aplicación que recopila información sobre el hardware y software de equipos que hay en la red que ejecutan el programa de cliente OCS («agente OCS de inventario»). Esta información la envían los agentes al servidor de inventariado. OCS puede utilizarse para visualizar el inventario a través de una interfaz web.
OCS Inventory ofrece la posibilidad de, además de realizar un inventariado, desplegar software en forma de scripts Bash en el equipo donde se ejecuta el agente.
El modus operandi sería el siguiente:
- El agente envía un inventario al servidor OCS
- El servidor procesa el inventario y comprueba si hay paquetes de software asignados para el despliegue en el equipo que ejecuta el agente que envía dicho inventario
- Si existen paquetes asignados a este agente, el servidor de comunicación y/o despliegue lo envía al agente mediante protocolo SSL
- El agente realiza un handshake con el servidor, descarga el paquete y lo ejecuta. Una vez ejecutado, devuelve un código que puede ser de éxito o de error. Se adjunta a continuación la tabla completa de casos de error y éxito.
| Código de estado | Significado |
| WAITING NOTIFICATION | El servidor está esperando comunicación del agente para notificar que hay algo para descargar. |
| NOTIFIED | El agente ha sido notificado sobre un paquete a descargar. Esperando el código de resultado. |
| SUCCESS | El agente ha descargado exitosamente un paquete y ha ejecutado comandos o ha almacenado datos extraídos. Con la acción «Lanzar», este estado podría completarse con el código de retorno de la ejecución. |
| ERR_ALREADY_SETUP | El paquete ya fue instalado previamente en este equipo. |
| ERR_BAD_ID | El agente es incapaz de descargar un paquete porque no puede encontrar la ID Del mismo en el servidor de despliegue. |
| ERR_BAD_DIGEST | Los datos descargados tienen un mal digest, por lo que el agente no ejecuta comandos asociados. |
| ERR_DOWNLOAD_PACK | El agente fue incapaz de descomprimir el fichero ZIP o TAR.GZ descargado. |
| ERR_BUILD | El agente fue incapaz de reconstruir los fragmentos del paquete. |
| ERR_EXECUTE | El agente fue incapaz de ejecutar el comando asociado al paquete. |
| ERR_CLEAN | El agente fue incapaz de limpiar el paquete descargado. |
| ERR_TIMEOUT | El agente fue incapaz de descargar durante el período DOWNLOAD_TIMEOUT. |
| ERR_ABORTED | El usuario canceló la ejecución del comando del paquete (ha escogido notificarlo, y le ha permitido cancelarlo). |
| ERR_EXECUTE_PACK | No utilizado |
OCS Inventory está formado por las siguientes partes:

- Agentes instalados en sistemas Windows o GNU/Linux: programas escritos en PERL
- Un servidor de gestión que se compone de:
-
- Servidor de comunicación: servidor escrito en PERL que recibe los inventariados de los agentes y los almacena en la base de datos.
- Servidor de despliegue: se encarga de desplegar software en los equipos agentes. Puede ser el mismo que el servidor de comunicación. Obligatorio Apache con SSL activado.
- Consola de administración: interfaz Web escrita en PHP y visible mediante navegador. Lee directamente de la base de datos.
- Instalación completa de OCS Inventory
En primer lugar debemos instalar tanto el agente como el servidor de comunicación, de despliegue y la consola de administración.
Lo ideal es que tengamos instalado un servidor Apache preparado y los módulos de PERL para los agentes y el servidor de comunicación. Instalamos lo necesario:
- neonigma@neonigma-desktop:~$ sudo apt-get install apache2 php5 perl mysql-server-5.1 libphp-pclzip php5-gd libapache2-mod-perl2 php5-mysql libxml-simple-perl libcompress-zlib-perl libdbi-perl libdbd-mysql-perl libapache-dbi-perl libnet-ip-perl libsoap-lite-perl
Ahora comenzamos instalando un agente en cualquier equipo que vaya a realizar un inventariado y enviarlo al servidor:
- neonigma@neonigma-desktop:~$ sudo apt-get install ocsinventory-agent
Continuamos con la consola de administración, que no la vamos a instalar de los repositorios porque suele dar algún que otro problema en la configuración:
- Descargamos la consola de administración Web:
- neonigma@neonigma-desktop:~$ wget http://launchpad.net/ocsinventory-server/stable-1.3/1.3.2/+download/OCSNG_UNIX_SERVER-1.3.2.tar.gz
- Lo movemos a nuestro servidor Apache:
- neonigma@neonigma-desktop:~$ sudo mv OCSNG_UNIX_SERVER-1.3.2.tar.gz /var/www
- Lo descomprimimos:
- neonigma@neonigma-desktop:~$ sudo tar xvzf OCSNG_UNIX_SERVER-1.3.2.tar.gz
- Entramos en el directorio:
- neonigma@neonigma-desktop:~$ cd OCSNG_UNIX_SERVER-1.3.2
- Comenzamos la instalación:
- neonigma@neonigma-desktop:~$ sudo ./setup.sh
No voy a detallar el proceso de instalación, está bien explicado aquí. Sólo voy a poner unos incisos a la explicación anterior, leedlos antes de seguirla y tenerlos en cuenta.
No os preocupéis si veis mensajes como:
- Checking for SOAP::Lite PERL module...
- *** Warning: PERL module SOAP::Lite is not installed !
- This module is only required by OCS Inventory NG SOAP Web Service.
- Do you wish to continue ([y]/n] ?
- Checking for XML::Entities PERL module...
- *** Warning: PERL module XML::Entities is not installed !
- This module is only required by OCS Inventory NG SOAP Web Service.
- Do you wish to continue ([y]/n] ?
Esto sólo se utiliza para el servicio Web (experimental y para desarrolladores), y no influye para el despliegue de software en los agentes.
En todo caso, debemos tener cuidado en estas respuestas:
- Which host is running database server [localhost] ?127.0.0.1
- OK, database server is running on host 127.0.0.1 ;-)
- Where to copy Administration Server static files for PHP Web Console
- [/usr/share/ocsinventory-reports] ?/var/www/ocsinventory-reports
- OK, using directory /var/www/ocsinventory-reports to install static files ;-)
- Where to create writable/cache directories for deployement packages and
- IPDiscover [/var/lib/ocsinventory-reports] ?/var/www/ocsinventory-reports
En los dos últimos casos casos, contestaré /var/www/ocsinventory-reports para almacenar tanto el servidor como los paquetes de despliegue en esa ruta.
Si tenemos problemas en la instalación, por ej. se sale de la misma por no estar los módulos PERL instalados, los instalamos a mano:
- perl -MDBD::mysql -e 1
- sudo perl -MCPAN -e shell
- # si nos pregunta, pulsamos INTRO
- install YAML
- install Apache::DBI
- install DBD::mysql
- install Compress::Zlib # si nos pregunta, pulsamos INTRO
- install XML::Simple
- install Net::IP
Continuamos con la instalación del servidor de comunicación desde los repositorios. Esto lo vamos a hacer en la máquina servidora.
- neonigma@neonigma-desktop:~$ sudo apt-get install ocsinventory-server
A partir de aquí tenemos un servidor OCS Inventory totalmente funcional.
Ahora, en la o las máquinas que vayan a utilizarse como clientes (puede ser la misma también si se quiere), instalaremos el agente de OCS Inventory (en el método de instalación escogemos http y en el nombre 127.0.0.1):
- neonigma@neonigma-desktop:~$ sudo apt-get install ocsinventory-agent
desde el que podemos mandar inventarios con la siguiente orden:
- neonigma@neonigma-desktop:~$ sudo ocsinventory-agent --server ip.ip.ip.ip
Sin embargo, lo que nos ocupa aquí es el poder desplegar software en los agentes, es decir, que cuando un agente envíe un inventariado, compruebe en el servidor de despliegue si hay paquetes para él. En caso afirmativo, el agente descargará el paquete tar.gz, lo descomprimirá y ejecutará el script que lleve dentro el fichero comprimido.
Para esto, vamos a utilizar el mismo equipo servidor en el que está instalado el servidor de comunicación en PERL, activando en éste el soporte SSL y convirtiéndolo también en servidor de despliegue.
Vamos a ejecutar los siguientes tres comandos para activar el soporte SSL en Apache:
- neonigma@neonigma-desktop:~$ sudo a2enmod ssl
- Enabling module ssl.
- See /usr/share/doc/apache2.2-common/README.Debian.gz on how to configure SSL and create self-signed certificates.
- Run '/etc/init.d/apache2 restart' to activate new configuration!
- neonigma@neonigma-desktop:~$ sudo a2ensite default-ssl
- Enabling site default-ssl.
- Run '/etc/init.d/apache2 reload' to activate new configuration!
- neonigma@neonigma-desktop:~$ sudo /etc/init.d/apache2 restart
Ahora nos vamos a apoyar del excelente tutorial de Vicente Navarro en este post.
<!–Concretamente, necesitamos sólo la parte que generará un certificado cacert.pem, esta parte está nombrada en el tutorial como Crear un certificado firmado por nuestra propia autoridad certificadora y haremos todos los pasos que se indican hasta llegar a la parte Cuidado con ponerle contraseña a la clave privada
Donde pone y cambiar la configuración del sitio para que lo use:, se refiere al archivo /etc/apache2/sites-enabled/default-ssl, donde tenemos que cambiar las rutas de SSLCertificateFile y SSLCertificateKeyFile.–>
Vamos a ver cómo crear un certificado firmado por nuestra propia autoridad certificadora, utilizando el script CA.pl de OpenSSL, que en sistemas tipo Debian está bajo /usr/lib/ssl/misc/.
Creamos un nuevo certificado raíz para la autoridad certificadora «jialvarez», de la empresa «Emergya».
- soporte@soporte-laptop:~/ocs_packages$ cd /usr/lib/ssl/misc/
- soporte@soporte-laptop:/usr/lib/ssl/misc$ sudo su
- [sudo] password for soporte:
- root@soporte-laptop:/usr/lib/ssl/misc$ ./CA.pl -newca
- CA certificate filename (or enter to create)
- Making CA certificate ...
- Generating a 1024 bit RSA private key
- ........++++++
- ....++++++
- writing new private key to './demoCA/private/cakey.pem'
- Enter PEM pass phrase: (por ejemplo, mipass)
- Verifying - Enter PEM pass phrase: (de nuevo escribimos mipass)
- -----
- You are about to be asked to enter information that will be incorporated
- into your certificate request.
- What you are about to enter is what is called a Distinguished Name or a DN.
- There are quite a few fields but you can leave some blank
- For some fields there will be a default value,
- If you enter '.', the field will be left blank.
- -----
- Country Name (2 letter code) [AU]:ES
- State or Province Name (full name) [Some-State]:Sevilla
- Locality Name (eg, city) []:Sevilla
- Organization Name (eg, company) [Internet Widgits Pty Ltd]:Emergya
- Organizational Unit Name (eg, section) []: Distros
- Common Name (eg, YOUR name) []:jialvarez
- Email Address []:jialvarez@emergya.es
- Please enter the following 'extra' attributes
- to be sent with your certificate request
- A challenge password []: (dejamos todos los campos extra vacios)
- An optional company name []:
- Using configuration from /usr/lib/ssl/openssl.cnf
- Enter pass phrase for ./demoCA/private/cakey.pem: (volvemos a escribir mipass)
- Check that the request matches the signature
- Signature ok
- Certificate Details:
- Serial Number:
- a3:a3:a2:5d:a5:13:44:ac
- Validity
- Not Before: Nov 2 14:49:20 2010 GMT
- Not After : Nov 1 14:49:20 2013 GMT
- Subject:
- countryName = ES
- stateOrProvinceName = Sevilla
- organizationName = Emergya
- organizationalUnitName = Distros
- commonName = jialvarez
- emailAddress = jialvarez@emergya.es
- X509v3 extensions:
- X509v3 Subject Key Identifier:
- 1C:E7:EA:B8:BF:21:00:77:64:5E:00:11:A5:28:76:75:A8:4D:67:D1
- X509v3 Authority Key Identifier:
- keyid:1C:E7:EA:B8:BF:21:00:77:64:5E:00:11:A5:28:76:75:A8:4D:67:D1
- DirName:/C=ES/ST=Sevilla/O=Emergya/OU=Distros/CN=jialvarez/emailAddress=jialvarez@emergya.es
- serial:A3:A3:A2:5D:A5:13:44:AC
- X509v3 Basic Constraints:
- CA:TRUE
- Certificate is to be certified until Nov 1 14:49:20 2013 GMT (1095 days)
- Write out database with 1 new entries
- Data Base Updated
Vale, ya somos autoridad certificadora. Ahora vamos a generar una clave privada y una petición de certificado para nuestro sitio web. Es de vital importancia saber que los datos a escribir aquí deben ser exactamente los mismos que los que se escribieron en el paso anterior.
- root@soporte-laptop:/usr/lib/ssl/misc$ ./CA.pl -newreq
- Generating a 1024 bit RSA private key
- .....................++++++
- .................++++++
- writing new private key to 'newkey.pem'
- Enter PEM pass phrase: (este es el password anterior, escribimos mipass)
- Verifying - Enter PEM pass phrase: (nuevamente mipass)
- -----
- You are about to be asked to enter information that will be incorporated
- into your certificate request.
- What you are about to enter is what is called a Distinguished Name or a DN.
- There are quite a few fields but you can leave some blank
- For some fields there will be a default value,
- If you enter '.', the field will be left blank.
- -----
- Country Name (2 letter code) [AU]:ES
- State or Province Name (full name) [Some-State]:Sevilla
- Locality Name (eg, city) []:Sevilla
- Organization Name (eg, company) [Internet Widgits Pty Ltd]:Emergya
- Organizational Unit Name (eg, section) []: Distros
- Common Name (eg, YOUR name) []:jialvarez
- Email Address []:jialvarez@emergya.es
- Please enter the following 'extra' attributes
- to be sent with your certificate request
- A challenge password []:
- An optional company name []:
- Request is in newreq.pem, private key is in newkey.pem
El último paso es firmar el certificado.
- root@soporte-laptop:/usr/lib/ssl/misc$ ./CA.pl -sign
- Using configuration from /usr/lib/ssl/openssl.cnf
- Enter pass phrase for ./demoCA/private/cakey.pem: (de nuevo especificamos mipass)
- Check that the request matches the signature
- Signature ok
- Certificate Details:
- Serial Number:
- a3:a3:a2:5d:a5:13:44:ad
- Validity
- Not Before: Nov 2 14:54:59 2010 GMT
- Not After : Nov 2 14:54:59 2011 GMT
- Subject:
- countryName = ES
- stateOrProvinceName = Sevilla
- localityName = Sevilla
- organizationName = Emergya
- organizationalUnitName = Distros
- commonName = jialvarez
- emailAddress = jialvarez@emergya.es
- X509v3 extensions:
- X509v3 Basic Constraints:
- CA:FALSE
- Netscape Comment:
- OpenSSL Generated Certificate
- X509v3 Subject Key Identifier:
- EE:52:FE:6C:FB:CD:42:00:AB:C4:81:06:4D:27:2B:BA:4C:AD:59:0B
- X509v3 Authority Key Identifier:
- keyid:1C:E7:EA:B8:BF:21:00:77:64:5E:00:11:A5:28:76:75:A8:4D:67:D1
- Certificate is to be certified until Nov 2 14:54:59 2011 GMT (365 days)
- Sign the certificate? [y/n]:y
- 1 out of 1 certificate requests certified, commit? [y/n]y
- Write out database with 1 new entries
- Data Base Updated
- Signed certificate is in newcert.pem
Con esto, tenemos cuatro ficheros generados, newcert.pem, newkey.pem y newreq.pem en /usr/lib/ssl/misc y cacert.pem, el más importante puesto que es el certificado raíz de la nueva autoridad certificadora, en /usr/lib/ssl/misc/demoCA.
Ahora movemos los ficheros necesarios a una ubicación mejor conocida, teniendo cuidado en esta operación pues los nombres y extensiones son muy similares.
- root@soporte-laptop:/usr/lib/ssl/misc$ mv newkey.pem /etc/ssl/private/ocs.key
- root@soporte-laptop:/usr/lib/ssl/misc$ mv newcert.pem /etc/ssl/certs/ocs.crt
Ahora editamos la configuración de nuestro sitio Web:
- root@soporte-laptop:/usr/lib/ssl/misc# cd /etc/apache2/sites-enabled/
- root@soporte-laptop:/etc/apache2/sites-enabled# vim default-ssl
Y modificamos estas líneas:
- SSLCertificateFile /etc/ssl/certs/ssl-cert-snakeoil.pem
- SSLCertificateKeyFile /etc/ssl/private/ssl-cert-snakeoil.key
por éstas (nótese ocs.crt y no ocs.pem):
- SSLCertificateFile /etc/ssl/certs/ocs.crt
- SSLCertificateKeyFile /etc/ssl/private/ocs.key
Y ya sólo nos queda reiniciar Apache:
- root@soporte-laptop:/usr/lib/ssl/misc# /etc/init.d/apache2 restart
- * Restarting web server apache2 apache2: Could not reliably determine the server's fully qualified domain name, using 127.0.1.1 for ServerName
- apache2: Could not reliably determine the server's fully qualified domain name, using 127.0.1.1 for ServerName
- Apache/2.2.14 mod_ssl/2.2.14 (Pass Phrase Dialog)
- Some of your private key files are encrypted for security reasons.
- In order to read them you have to provide the pass phrases.
- Server 127.0.1.1:443 (RSA)
- Enter pass phrase:
- OK: Pass Phrase Dialog successful.
<!–Una vez generado el certificado cacert.pem firmado por nuestra propia autoridad certificadora, reiniciado el servidor (nos pedirá el password proporcionado al generar el certificado) –>
Ya podemos instalar la consola de administración accediendo por primera vez a nuestro servidor SSL:
- https://localhost/ocsreports/install.php
Seguimos los pasos para configurar la base de datos y listo. Una vez terminado el proceso, vamos a:
- https://localhost/ocsreports/
y entramos con usuario admin y contraseña admin
A partir de aquí podemos realizar nuestro primer inventariado con cualquier agente (sudo ocsinventory-agent –server 192.168.1.191), nos vamos al directorio del servidor /var/lib/ocsinventory-agent/http:__192.168.1.191_ocsinventory y copiamos allí el fichero cacert.pem. Hacemos especial hincapié en que, aunque el equipo agente y el servidor sean el mismo, debe configurarse siempre la dirección EN LA RED del equipo servidor, y no 127.0.0.1 o localhost.
- neonigma@neonigma-desktop:/var/lib/ocsinventory-agent/http:__192.168.1.191_ocsinventory$ sudo cp /usr/lib/ssl/misc/demoCA/cacert.pem .
En este punto, ya podemos crear un paquete con un script para desplegar en cualquier agente.
- Creación y despliegue de scripts
Vamos a habilitar mediante la consola de administración el despliegue o distribución de software. Para ello vamos al menú de configuración:
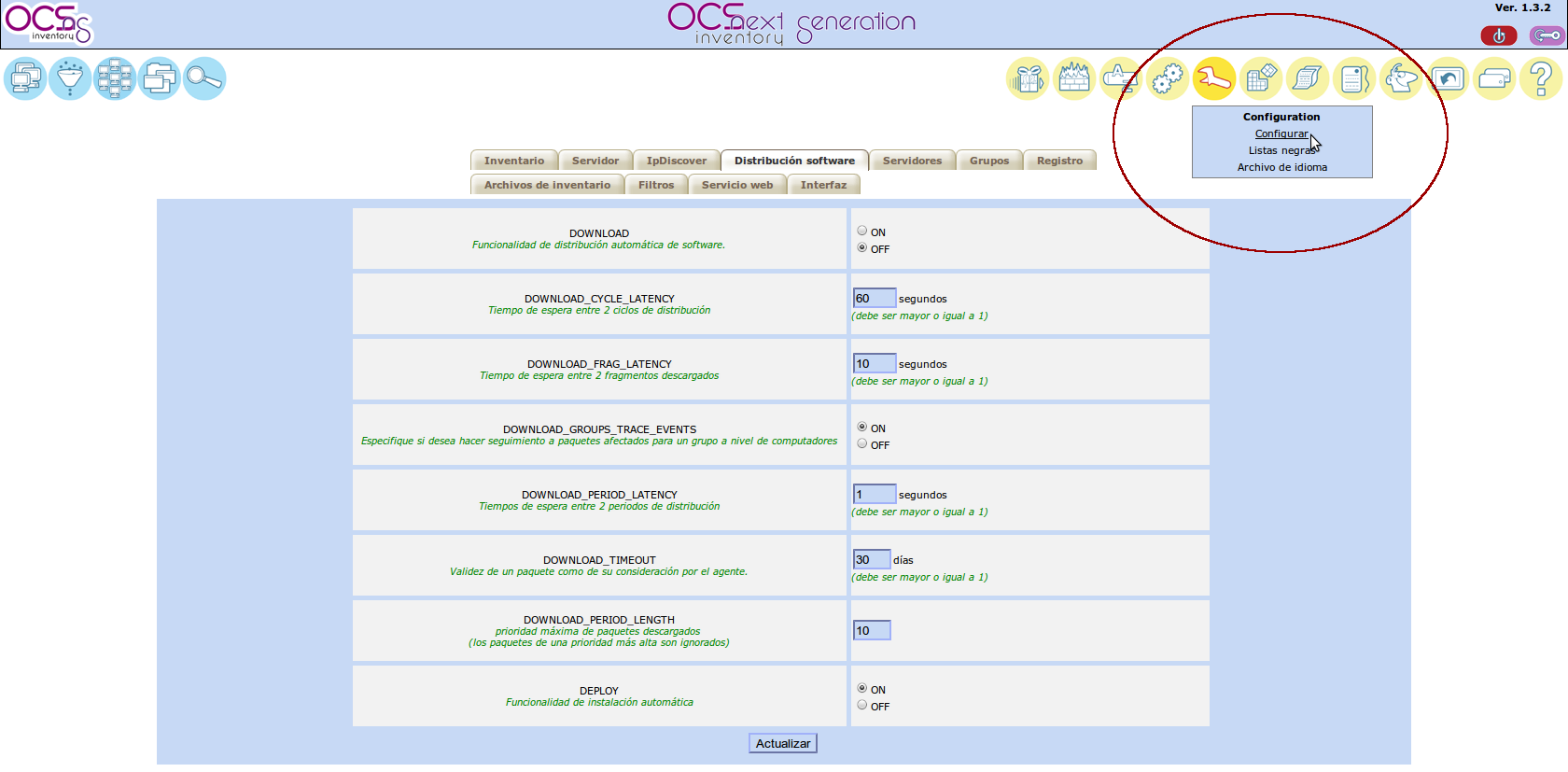
y activamos la opción correspondiente, bajando además el tiempo de ciclo de latencia que es algo elevado:
Ahora vamos a crear un script cualquiera, lo vamos a asignar a un equipo en concreto (en el que se ejecuta un agente) y vamos a hacer la prueba de despliegue. El script que vamos a utilizar puede ser este mismo, lo llamamos myscript por ejemplo:
- #!/bin/bash
- echo "¡¡ESTOY EJECUTANDO SOFTWARE DESPLEGADO CON OCS INVENTORY!!";
- echo "Información sobre tu CPU";
- lscpu
- sudo apt-get install teeworlds --assume-yes
- echo "¡¡JUEGO INSTALADO, A DISFRUTAR DE LAS VACACIONES!!";
Vamos a comprimir este script:
- neonigma@neonigma-desktop:~$ tar cvzf myscript.tar.gz myscript
Y ahora vamos a crear el paquete software en la consola de administración de OCS Inventory. Vamos a la Web y escogemos la opción Crear del menú Distribución software.
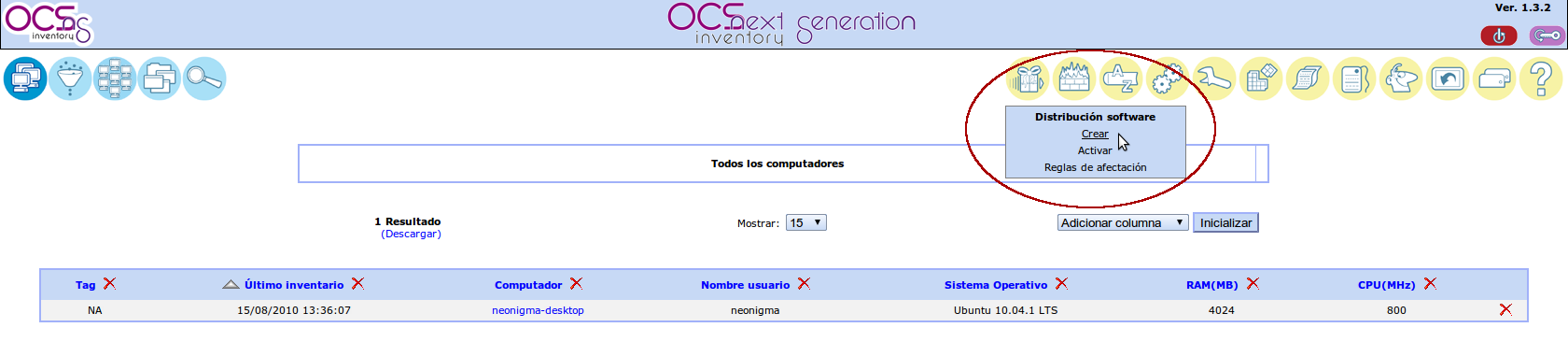
Introducimos los datos del nuevo paquete, indicando que tenemos un fichero comprimido myscript.tar.gz y que lanzaremos un script que tiene en su interior llamado myscript con prioridad 5 (podemos ponerle prioridad 0 que es prioridad absoluta).
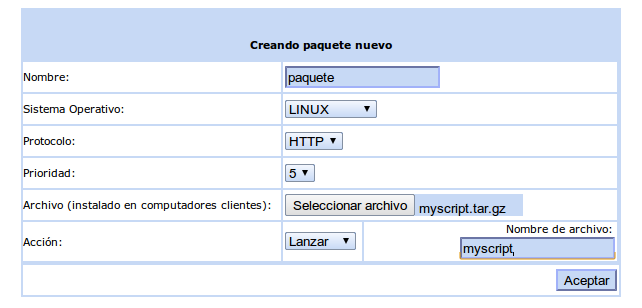
Si al aceptar nos da el mensaje de error ERROR: can’t create or write in /var/lib/ocsinventory-reports/download/xxxxxxxxx folder, please refresh when fixed. (or try disabling php safe mode), tenemos que cambiar estas rutas en la base de datos. Podemos hacerlo de la siguiente manera:
- neonigma@neonigma-desktop:~$ mysql -u root -p
- mysql> UPDATE config SET TVALUE="/var/www/ocsinventory-reports" WHERE NAME="DOWNLOAD_PACK_DIR"
- mysql> UPDATE config SET TVALUE="/var/www/ocsinventory-reports" WHERE NAME="IPDISCOVER_IPD_DIR"
y reiniciamos el proceso, creando de nuevo el paquete.
A continuación dejamos los siguientes datos como están porque nuestro paquete no es muy grande y no queremos fragmentar su envío. Pulsamos en Enviar y el paquete queda creado.
Realizamos ahora el proceso de activación del paquete. Escogemos la opción activar del menú Distribución software.
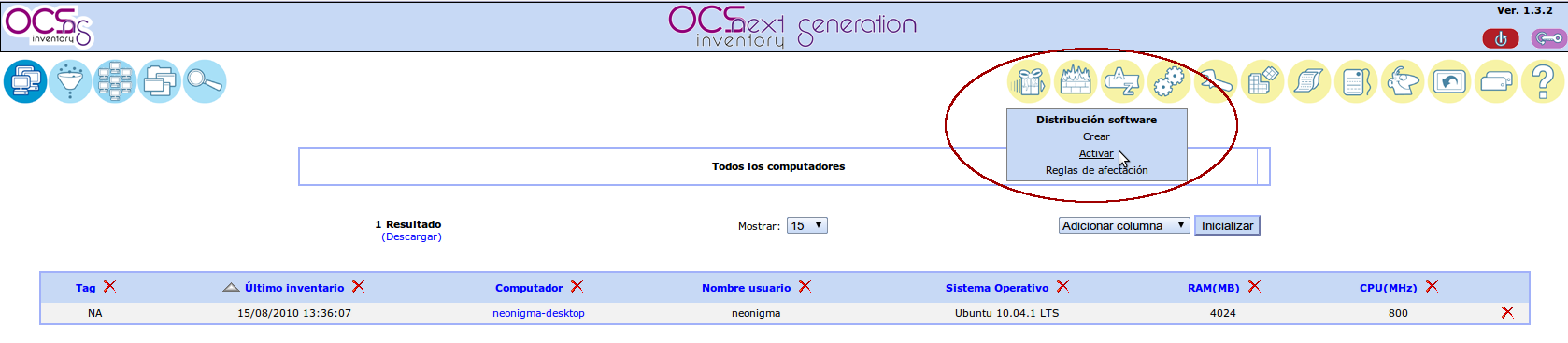
Nos vamos a la fila que muestra el paquete recién creado y pulsamos en el botón Activar.
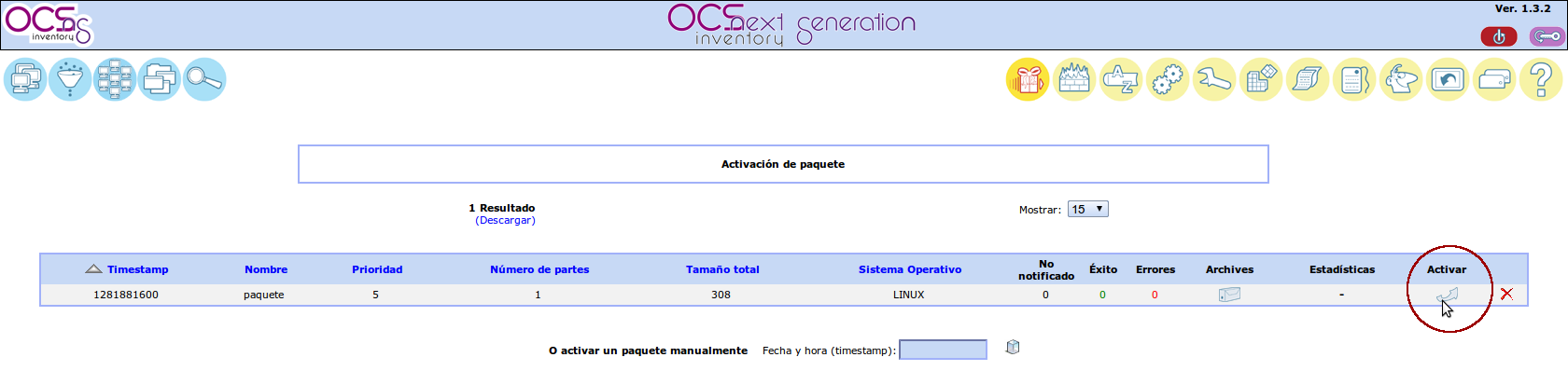
Dejamos marcada Activación manual y especificamos como URL https y como Partes URL la misma cadena https://192.168.1.191/ocsinventory-reports/download
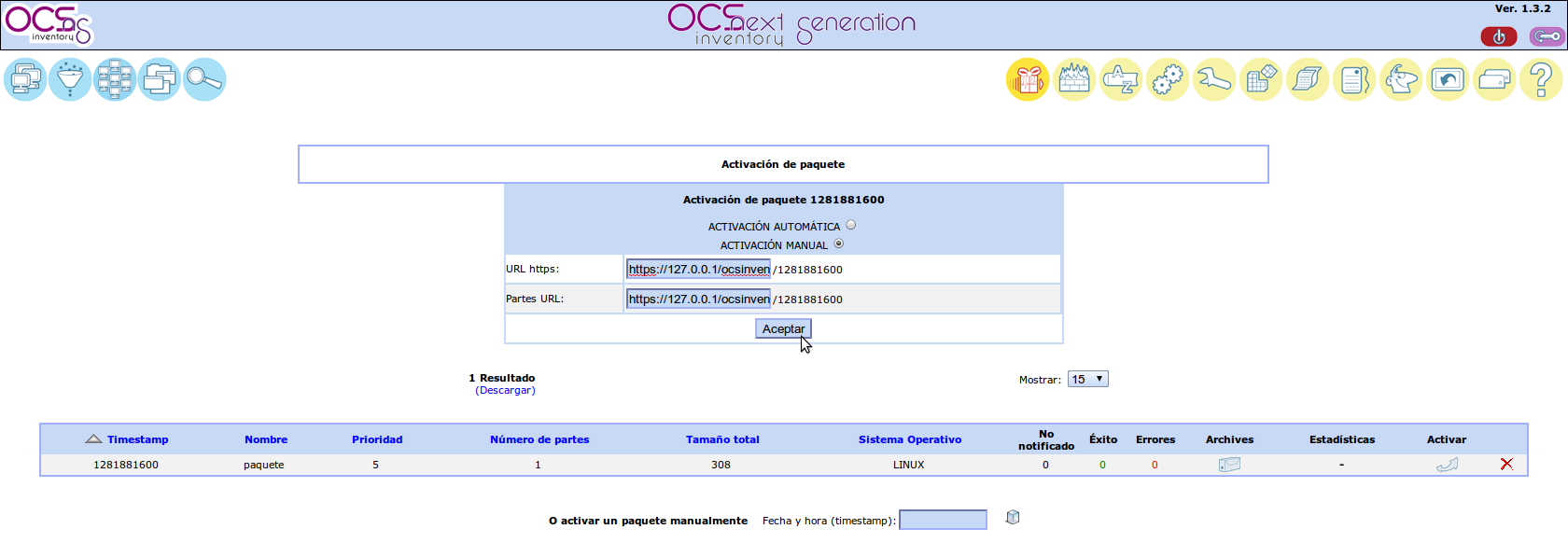
Al aceptar, se nos informa de que el paquete ya se ha activado y lo podemos afectar. Aquí, afectar un paquete se refiere a asignarlo a un equipo o a un conjunto de ellos.
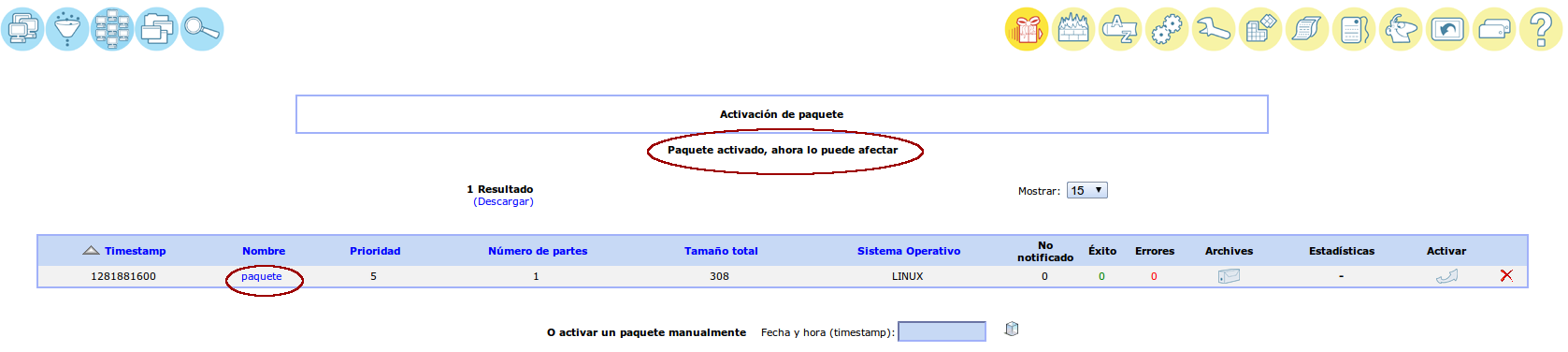
El último paso es asignar o afectar un paquete a un equipo. Para ello escogemos un equipo de la lista de los que tenemos inventariados:

Pulsamos en la opción Personalizar de la lista de opciones disponibles para un equipo concreto:

Pulsamos en adicionar paquete:
De la lista de paquetes, localizamos la fila del paquete deseado y pulsamos en el botón Afectar. A la pregunta de si estamos seguros, respondemos que sí.

Podemos ver que el paquete queda asignado al equipo y esperando notificación de envío.

Ahora la ejecución de un inventariado por parte del agente instalado en el equipo afectado, provocará que éste se descargue del servidor el paquete disponible para él. Lo vemos:
- neonigma@neonigma-desktop:~$ sudo ocsinventory-agent --debug --info --logfile logfile.log
- [sudo] password for neonigma:
- DOWNLOAD: Writing config file.
- DOWNLOAD: Making working directory for 1281884908.
- DOWNLOAD: Retrieving info file for 1281884908
- DOWNLOAD: Initialize ssl layer...
- DOWNLOAD: Connect to server: 192.168.1.191/ocsinventory-reports/download...
- DOWNLOAD: Starting SSL connection...
- DOWNLOAD: Info file:
- DOWNLOAD: Success. :-)
- DOWNLOAD: Beginning work. I am 26331.
- DOWNLOAD: Checking timeout for 1281884908... OK
- DOWNLOAD: New period. Nb of cycles: 10
- DOWNLOAD: Now pausing for a cycle latency => 5 seconds
- DOWNLOAD: Now pausing for a cycle latency => 5 seconds
- DOWNLOAD: Now pausing for a cycle latency => 5 seconds
- DOWNLOAD: Now pausing for a cycle latency => 5 seconds
- DOWNLOAD: Downloading 1281884908-1
- ...
- DOWNLOAD: Success :-)
- DOWNLOAD: Now pausing for a fragment latency => 10 seconds
- DOWNLOAD: Now pausing for a cycle latency => 5 seconds
- DOWNLOAD: Now pausing for a cycle latency => 5 seconds
- DOWNLOAD: Now pausing for a cycle latency => 5 seconds
- DOWNLOAD: Now pausing for a cycle latency => 5 seconds
- DOWNLOAD: Now pausing for a cycle latency => 5 seconds
- DOWNLOAD: Download of 1281884908... Finished.
- DOWNLOAD: Execute orders for package 1281884908.
- DOWNLOAD: Building package for 1281884908.
- DOWNLOAD: Checking signature for ./1281884908/tmp/build.tar.gz.
- DOWNLOAD: Digest format: Hexadecimal
- DOWNLOAD: Digest algo: MD5
- DOWNLOAD: Digest OK...
- => retrieving tar...
- => tar is at /bin/tar
- myscript
- DOWNLOAD: Building of 1281884908... Success.
- DOWNLOAD: Launching myscript...
- ¡¡ESTOY EJECUTANDO SOFTWARE DESPLEGADO CON OCS INVENTORY!!
- Información sobre tu CPU
- Architecture: i686
- CPU op-mode(s): 64-bit
- CPU(s): 4
- Thread(s) per core: 1
- Core(s) per socket: 4
- CPU socket(s): 1
- Vendor ID: AuthenticAMD
- CPU family: 16
- Model: 4
- Stepping: 3
- CPU MHz: 800.000
- Virtualization: AMD-V
- L1d cache: 64K
- L1i cache: 64K
- L2 cache: 512K
- L3 cache: 6144K
- Reading package lists... Done
- Building dependency tree
- Reading state information... Done
- The following extra packages will be installed:
- teeworlds-data
- Suggested packages:
- teeworlds-server
- The following NEW packages will be installed:
- teeworlds teeworlds-data
- 0 upgraded, 2 newly installed, 0 to remove and 5 not upgraded.
- Need to get 5288kB of archives.
- After this operation, 8364kB of additional disk space will be used.
- Get:1 http://mirrors.nfsi.pt/ubuntu/ lucid/universe teeworlds-data 0.5.1-3ubuntu1 [5114kB]
- Get:2 http://mirrors.nfsi.pt/ubuntu/ lucid/universe teeworlds 0.5.1-3ubuntu1 [174kB]
- Fetched 5288kB in 4s (1209kB/s)
- Selecting previously deselected package teeworlds-data.
- (Reading database ... 274481 files and directories currently installed.)
- Unpacking teeworlds-data (from .../teeworlds-data_0.5.1-3ubuntu1_all.deb) ...
- Selecting previously deselected package teeworlds.
- Unpacking teeworlds (from .../teeworlds_0.5.1-3ubuntu1_i386.deb) ...
- Processing triggers for man-db ...
- Processing triggers for desktop-file-utils ...
- Processing triggers for python-gmenu ...
- Rebuilding /usr/share/applications/desktop.C.cache...
- Processing triggers for python-support ...
- Setting up teeworlds-data (0.5.1-3ubuntu1) ...
- Setting up teeworlds (0.5.1-3ubuntu1) ...
- ¡¡JUEGO INSTALADO, A DISFRUTAR DE LAS VACACIONES!!
- DOWNLOAD: Package 1281884908... Done. Sending message...
- DOWNLOAD: Sending message for 1281884908, code=SUCCESS_0.
- DOWNLOAD: Cleaning 1281884908 package.
- unlink 1281884908/task_done
- unlink 1281884908/done
- unlink 1281884908/since
- unlink 1281884908/tmp/myscript
- rmdir tmp
- unlink 1281884908/info
- unlink 1281884908/task
- unlink 1281884908/1281884908-1
- rmdir 1281884908
- DOWNLOAD: Now pausing for a fragment latency => 10 seconds
- DOWNLOAD: Now pausing for a cycle latency => 5 seconds
- DOWNLOAD: No more package to download.
- DOWNLOAD: End of work...
REFERENCIAS
http://www.ocsinventory-ng.org/
http://es.wikipedia.org/wiki/OCS_Inventory
http://wiki.intropedro.com/index.php?title=Instalar_el_servidor_de_ocs_inventory
http://www.vicente-navarro.com/blog/2009/02/22/crear-los-certificados-ssl-para-nuestro-servidor-web-https-con-apache-openssl-y-debian-lenny
 A 4 personas les gusta esta entrada
A 4 personas les gusta esta entrada